Im Vergleich von Horizontal vs. Vertical Pod Autoscaling in Kubernetes zeigt sich deutlich, wie wichtig die strategische Auswahl des richtigen Skalierungsmodells für die Performance und Effizienz Ihrer Cloud-Architektur ist. Beide Methoden bieten spezielle Vorteile, je nach Workload und Infrastruktur – eine fundierte Entscheidung ist entscheidend für erfolgreiches Pod Autoscaling.
Zentrale Punkte
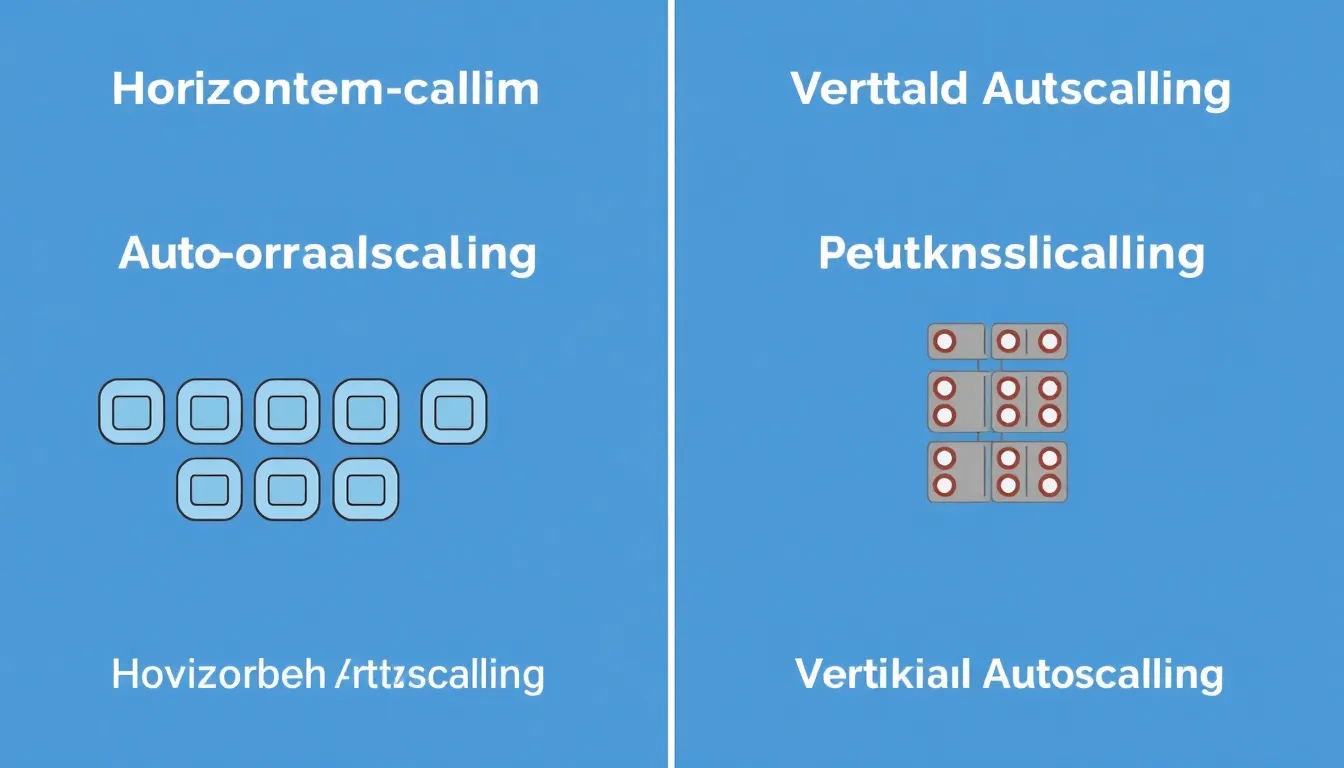
- Horizontal Pod Autoscaler (HPA) erhöht oder verringert die Anzahl der Pod-Replikate dynamisch nach Last.
- Vertical Pod Autoscaler (VPA) passt CPU- und RAM-Anforderungen einzelner Pods an.
- HPA eignet sich optimal für stateless Anwendungen und stark variierende Lasten.
- VPA adressiert rechenintensive, konstante Workloads mit feinen Ressourcenanpassungen.
- Die Kombination von HPA und VPA erfordert sorgfältige Abstimmung der Skalierungsstrategien.
Pod Autoscaling: Grundlagen und Bedeutung
Pod Autoscaling ist unverzichtbar, um Kubernetes-Cluster effizient zu betreiben und Lastschwankungen professionell abzufedern. Kubernetes nutzt dafür den Horizontal Pod Autoscaler (HPA) und den Vertical Pod Autoscaler (VPA). Während HPA zusätzliche Instanzen einer Anwendung bereitstellt, justiert VPA die Ressourcen einzelner Instanzen dynamisch nach Bedarf. Durch skalierfähige Architekturen lassen sich sowohl Kosten als auch Infrastrukturaufwand deutlich optimieren. Wer effektive Cloud-Skalierungsstrategien verfolgt, kommt an sauber aufgesetztem Autoscaling in Kubernetes nicht vorbei.
Im Kern sorgt Pod Autoscaling dafür, dass Ressourcen genau dort zur Verfügung stehen, wo sie benötigt werden. Diese Dynamik ist in modernen Microservice-Architekturen essenziell, um flexibel auf Nutzerspitzen oder größere Datenverarbeitungsaufträge reagieren zu können. Gleichzeitig kann eine intelligente Skalierung verhindern, dass zu viele Ressourcen verschwendet werden, wenn Dienste kaum ausgelastet sind. So gelingt eine Balance aus Kostenkontrolle und hoher Performance.
Ein weiterer Aspekt ist die klare Definition von Richtwerten (Metriken), an denen sich das Autoscaling orientiert. Neben der CPU- und Speicher-Auslastung spielen in manchen Anwendungen auch Netzwerkdurchsatz, Anzahl aktiver Verbindungen oder benutzerdefinierte Metriken eine Rolle. Das Ziel bleibt jedoch stets gleich: Die Applikation soll performen, ohne unnötige Ressourcen zu blockieren.
Funktionsweise von Horizontal Pod Autoscaler in Kubernetes
Der Horizontal Pod Autoscaler reagiert auf Echtzeitmetriken wie CPU-Auslastung oder nutzerspezifische Metriken. Liegt die durchschnittliche Pod-Auslastung über einem definierten Schwellenwert, startet Kubernetes automatisch weitere Pods. Sinkt die Auslastung, entfernt HPA überzählige Pods wieder und reduziert so unnötige Ressourcenverschwendung. Standardmäßig erfolgt die Überprüfung aller 15 Sekunden. Dadurch entstehen hochverfügbare Systeme, die Schwankungen schnell kompensieren können – ideal etwa für E-Commerce-Plattformen oder APIs, bei denen die Zugriffe stündlich variieren.
Ein praktisches Beispiel: Sie betreiben einen Onlineshop mit täglich wechselnden Spitzen. Morgens besuchen Kunden den Shop, mittags sinkt die Aktivität, abends steigt sie wieder sprunghaft an. Mit HPA können Sie automatisch mehr Pod-Replikate anlegen, wenn die CPU- oder RAM-Nutzung der vorhandenen Pods gewisse Schwellen überschreitet. Nachts, wenn nur wenige Zugriffe stattfinden, wird die Pod-Anzahl reduziert, was Kosten und Ressourcen spart. Wichtig ist dabei, die HPA-Konfiguration regelmäßig zu überwachen und feinzujustieren, damit die Reaktionen weder zu hektisch noch zu langsam erfolgen.

Vertikale Pod Autoskalierung: Ressourcenoptimierung pro Instanz
Im Gegensatz dazu analysiert der Vertical Pod Autoscaler stetig die tatsächliche Nutzung von CPU und RAM innerhalb einzelner Pods. Basierend auf historischen und aktuellen Daten schlägt VPA entweder neue Ressourcenlimits vor oder wendet diese direkt an. Veränderungen an Ressourcen führen meistens zu einem Pod-Neustart. Deshalb eignet sich VPA exzellent für langlebige, spezialisierte Workloads wie Batch-Processing oder Machine-Learning-Aufgaben. Diese Strategie reduziert auch unnötigen Overhead auf Clusterebene, besonders bei limitierter Hardwarebasis.
Gerade in datenintensiven Szenarien, etwa beim Training komplexer Modelle oder bei Massendatenverarbeitung, zeigt VPA seine Stärken. Ein Pod, der zunächst mit zu geringen Ressourcenzuweisungen startet, kann durch die vertikale Skalierung genau die Menge an CPU und RAM erhalten, die er wirklich braucht. So vermeiden Sie Engpässe, ohne gleich zahlreiche Pod-Replikate anlegen zu müssen, die dann womöglich nicht gleichmäßig ausgelastet wären.

Allerdings sollte jedem klar sein, dass vertikale Skalierungen bei Anwendungen mit sehr kurzen Lebenszyklen oder stateless Services eventuell weniger sinnvoll sind. Hier sorgt die Kombination von Neustarts und gelegentlichen Spitzenlasten eher für eine unruhige Laufzeitumgebung. Deshalb ist es immer sinnvoll, vor dem Einsatz von VPA die Workload-Charakteristika zu analysieren. Ich empfehle hierbei ein genaues Monitoring aller relevanten Parameter über mehrere Tage oder Wochen, um verlässliche Daten über Auslastung und Ressourcenbedarf zu erhalten.
Vergleich: Horizontal vs. Vertical Pod Autoscaling in Kubernetes
Je nach Zielsetzung unterscheiden sich HPA und VPA wesentlich. Eine strukturierte Übersicht zeigt die Besonderheiten auf einen Blick:
| Kriterium | HPA | VPA |
|---|---|---|
| Skalierungsauslöser | Über oder unter definierten Lastmetriken | Tatsächlicher Ressourcenbedarf einzelner Pods |
| Skalierungsmethode | Mehr oder weniger Pod-Replikate | Anpassung von CPU-/RAM-Anforderungen |
| Einsatzbereich | Stateless Web-Anwendungen, APIs | Datenbanken, Batch-Workloads, Machine Learning |
| Downtime | Keine | Möglich (Restart der Pods bei Anpassungen) |
| Komplexität | Relativ niedrig | Höher, erfordert Zusatzinstallation |
| Kubernetes-Integration | Standard | Optionales Addon |
Diese Gegenüberstellung macht deutlich: Beide Ansätze können in verschiedenen Szenarien den entscheidenden Unterschied ausmachen. Statt also lediglich auf eine Methode zu setzen, kann eine hybride Lösung mehr Flexibilität bieten, sofern die jeweiligen Workloads und die Clusterarchitektur die Kombination sinnvoll unterstützen.
Wann HPA oder VPA sinnvoller ist
Für stateless Webanwendungen und stark schwankende Online-Dienste greife ich stets auf den Horizontal Pod Autoscaler zurück. Hier lässt sich Traffic ideal auf viele Pods verteilen, ohne Ressourcenkonflikte zu riskieren. Rechenintensive oder speicherhungrige Prozesse profitieren dagegen enorm vom Einsatz eines Vertical Pod Autoscalers. Gerade in Data-Science-Projekten oder Machine Learning Pipelines macht das flexible Anpassen der Ressourcen für einzelne Container die Abläufe wesentlich effizienter.

Verbunden damit ist auch die Frage, wie oft sich die Lastmuster ändern. Wenn eine Anwendung täglichen, wöchentlichen oder saisonalen Schwankungen unterliegt, kann HPA rasch reagieren und Pods auf- oder abbauen, um den aktuellen Bedarf zu decken. VPA hingegen ist ideal, wenn einzelne Pods eine kontinuierliche Rechenzuteilung benötigen, etwa für langlaufende Jobs. Eine manuelle oder gar unbedachte Kombination beider Strategien ohne klares Regelwerk kann jedoch dazu führen, dass sich HPA und VPA widersprechen und unbeabsichtigt zusätzliche Pods gestartet oder zu großzügige Ressourcen angefordert werden.
Herausforderungen bei kombinierter Nutzung von HPA und VPA
Die kombinierte Verwendung von HPA und VPA erhöht die Skalierbarkeit, birgt aber Risiken. Der Grund: HPA überwacht meist CPU-Anteile, während VPA sowohl CPU- als auch RAM-Werte manipuliert. Verändert VPA die Ressourcen eines Pods, erkennt HPA eine geringere prozentuale Auslastung und könnte unnötige neue Pods starten. Dadurch entstehen Kosten und Instabilitäten. Setzen Sie bei kombinierter Nutzung Policy-Regeln, die solche Konflikte vermeiden. Ich empfehle zusätzlich dediziertes Monitoring, um unvorhergesehene Skalierungsmuster frühzeitig zu erkennen.

Ein weiterer Aspekt ist die Rolle der historischen Daten. Damit VPA akkurat Vorschläge für Ressourcenanpassungen machen kann, analysiert es in der Regel den Ressourcenverbrauch über einen gewissen Zeitraum. HPA hingegen basiert häufig nur auf den aktuellen Metriken aus dem Metrics-Server. Werden Pods durch VPA ständig neugestartet, fehlen unter Umständen verlässliche Langzeitdaten, was die Prognosen und Handlungsvorschläge verfälschen kann. Eine gesunde Balance aus Stabilität und Reaktionsfähigkeit ist daher die Basis, um mit beiden Autoscalern erfolgreich zu sein.
Ebenso ist zu berücksichtigen, dass Node-Autoscaling hinzukommen kann. Viele Kubernetes-Setups nutzen nämlich die Möglichkeit, bei steigender Last automatisch neue Nodes hinzuzufügen. HPA und VPA interagieren mit diesem Mechanismus indirekt, da mehr oder weniger Pods auch den Bedarf an Nodes beeinflussen. Eine schlechte Abstimmung zwischen Pod-Autoscaling und Node-Autoscaling kann zu ungenutzten oder überlasteten Nodes führen. Es lohnt sich, hier klare Metriken und Schwellenwerte zu definieren, sodass das gesamte System effizient zusammenwirkt.
Best Practices für optimales Pod Autoscaling
Erfolgreiches Pod Autoscaling setzt korrekte Konfigurationen und konsequentes Monitoring voraus. Hier einige zentrale Empfehlungen:
- Definieren Sie klare Resource Requests und Limits für jeden Container. Ohne nachvollziehbare Limits bleibt Autoscaling ineffektiv.
- Überwachen Sie aktiv sowohl Auslastungstrends als auch Skalierungsentscheidungen über ein zentrales Monitoring-Tool.
- Simulieren Sie mögliche Lastspitzen regelmäßig mithilfe von Lasttests, um Schwächen frühzeitig zu erkennen.
- Beachten Sie die Empfehlungen aus Ressourcennutzung und Isolierung von Containern für optimierte Skalierungsentscheidungen.
Weiterführend sollten Sie Ihre Anwendungen in kleine, verantwortliche Einheiten zerlegen, um den Ressourcenbedarf möglichst präzise steuern zu können. Microservices, die klar definierte Aufgaben übernehmen, lassen sich leichter skalieren als monolithische Anwendungen, die viele unterschiedliche Funktionen vereinen. Kombinieren Sie diesen Ansatz mit einer Rollout-Strategie, die Downtimes minimiert, indem neue Pods vor dem Beenden alter Pods in Betrieb genommen werden.
Gerade wenn Sie HPA und VPA im Tandem nutzen möchten, ist ein gründliches Chaos-Testing sinnvoll. Dabei werden bewusst Lastspitzen und Fehlerszenarien provoziert, um zu beobachten, wie sich die skalierenden Komponenten gegenseitig beeinflussen. Hier kann sich zeigen, ob etwa VPA zu häufig Pod-Restarts durchführt und damit HPA triggert, mehr Replikate zu starten, was letztlich mehr Schaden als Nutzen bringt. Solche Tests decken Schwachstellen auf und erlauben Ihnen, die Parameter für beide Autoscaler zielgerichtet zu justieren.
Implementierung leicht gemacht: Tools und Hilfsmittel
Um die Implementierung von HPA und VPA zu vereinfachen, nutze ich gezielt Kubernetes-Werkzeuge wie Helm Charts oder deklarative Overlays. Besonders geeignet finde ich Lösungen, die die Konfiguration übersichtlich halten und Updates der Skalierungsparameter leichter ermöglichen. Wer den Vergleich Helm Charts vs. Kustomize Overlays versteht, kann seine Skalierungsstrategien effizient anpassen.
Native Kubernetes-Komponenten wie Metrics Server, Custom Metrics APIs und External Metrics APIs bieten zudem zahlreiche Einsichten in das Lastverhalten, um die Skalierungslogik noch besser zu justieren. In fortgeschrittenen Setups lassen sich eigene Metriken integrieren, die spezifisch auf Ihre Anwendung zugeschnitten sind, zum Beispiel die Dauer einer Datenbankabfrage oder die Anzahl laufender Transaktionen. Diese Metriken können als Auslöser für HPA dienen, was die Genauigkeit der Skalierungsentscheidungen deutlich erhöht.
Im Alltag unterstützt auch die predictive Autoscaling, bei dem Tools historische Daten analysieren und proaktiv Skalierungen vorschlagen, ehe Engpässe auftreten. Dadurch vermeiden Sie Situationen, in denen Pods erst neu bereitgestellt werden, wenn Nutzer bereits verzögerte Antwortzeiten spüren. Für besonders kritisch agierende Systeme kann das einen entscheidenden Wettbewerbsvorteil bedeuten, weil die Reaktions- und Ausfallsicherheit deutlich steigt.

Ein wichtiger Helfer für die Fehlersuche und Feinjustierung ist schließlich das Logging und Tracing. Es lohnt sich, ausführliche Logs zum Ressourcenverbrauch zu speichern, um rückblickend festzustellen, wie sich HPA und VPA verhalten haben. Kombinieren Sie diese Informationen mit Distributed Tracing, um zu sehen, ob es zu Performanceproblemen in bestimmten Microservices kommt, deren Einfluss eventuell die Skalierungsentscheidungen verzerren könnte. Solche Detailinformationen sind Gold wert, wenn es darum geht, ein stabiles Produktivsystem aufzubauen.
Zusammenfassung: Flexible Skalierung macht den Unterschied
Ob horizontal oder vertikal – jede Pod Autoscaling-Strategie hat spezifische Stärken. Webanwendungen profitieren meist von schnellen horizontalen Skalierungen über HPA. Rechenintensive Workloads erreichen mit VPA eine effiziente Ressourcenverteilung. Die Kombination beider Methoden kann die beste Lösung sein, erfordert jedoch abgestimmte Monitoringsysteme und sinnvolle Limits. Nur eine sorgfältig gewählte und implementierte Skalierungsstrategie stellt sicher, dass Kubernetes-Umgebungen sowohl unter Spitzenlasten als auch in ruhigeren Phasen stabil, performant und kosteneffizient bleiben.

